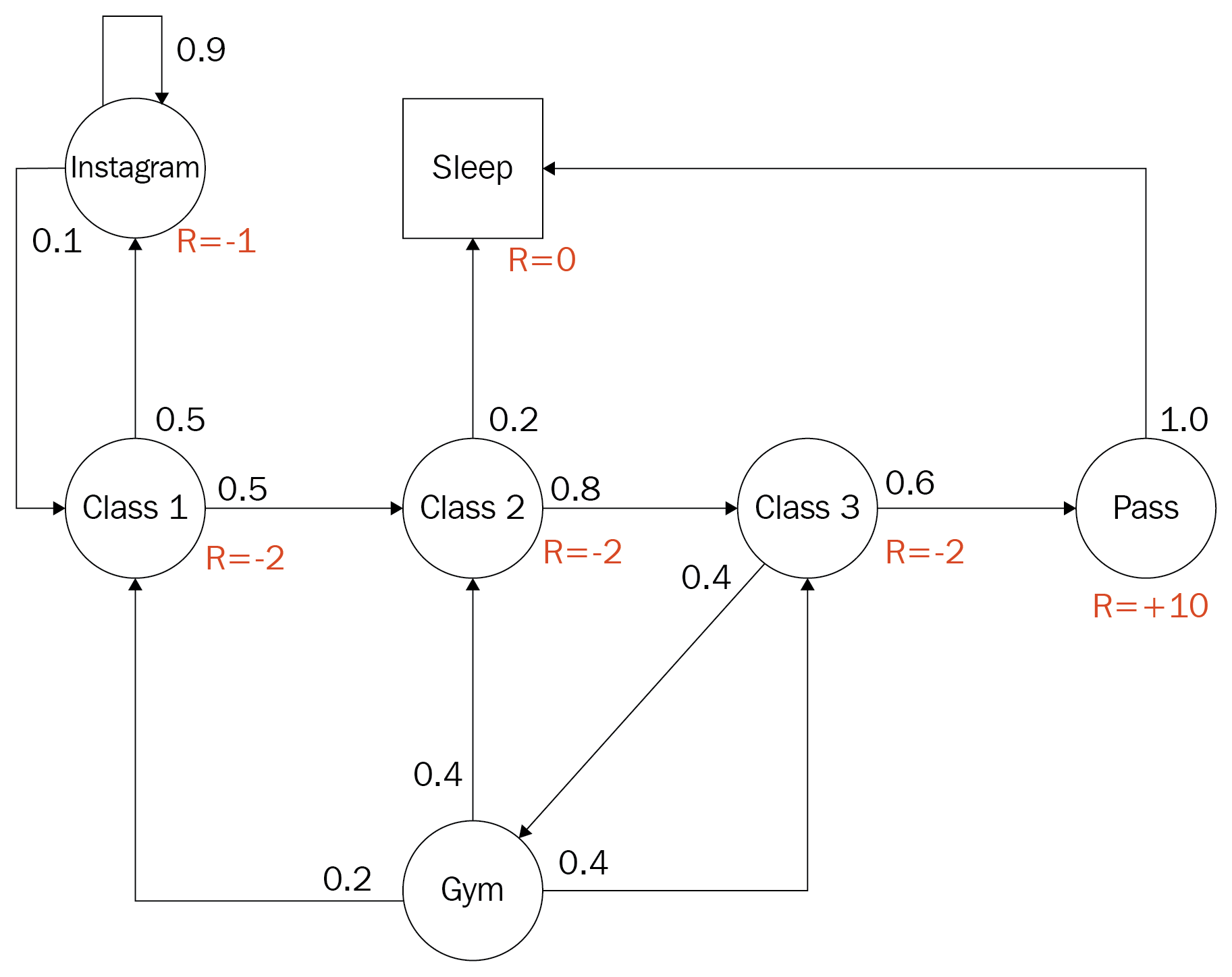
In RL, the agent learns from the environment by interpreting the state signal. The state signal from the environment needs to define a discrete slice of the environment at that time. For example, if our agent was controlling a rocket, each state signal would define an exact position of the rocket in time. State, in that case, may be defined by the rocket's position and velocity. We define this state signal from the environment as a Markov state. The Markov state is not enough to make decisions from, and the agent needs to understand previous states, possible actions, and any future rewards. All of these additional properties may converge to form a Markov property, which we will discuss further in the next section.
-
Book Overview & Buying

-
Table Of Contents

-
Feedback & Rating

Hands-On Reinforcement Learning for Games
By :
Hands-On Reinforcement Learning for Games
By:
Overview of this book
With the increased presence of AI in the gaming industry, developers are challenged to create highly responsive and adaptive games by integrating artificial intelligence into their projects. This book is your guide to learning how various reinforcement learning techniques and algorithms play an important role in game development with Python.
Starting with the basics, this book will help you build a strong foundation in reinforcement learning for game development. Each chapter will assist you in implementing different reinforcement learning techniques, such as Markov decision processes (MDPs), Q-learning, actor-critic methods, SARSA, and deterministic policy gradient algorithms, to build logical self-learning agents. Learning these techniques will enhance your game development skills and add a variety of features to improve your game agent’s productivity. As you advance, you’ll understand how deep reinforcement learning (DRL) techniques can be used to devise strategies to help agents learn from their actions and build engaging games.
By the end of this book, you’ll be ready to apply reinforcement learning techniques to build a variety of projects and contribute to open source applications.
Table of Contents (19 chapters)
Preface
Section 1: Exploring the Environment
 Free Chapter
Free Chapter
Understanding Rewards-Based Learning
Dynamic Programming and the Bellman Equation
Monte Carlo Methods
Temporal Difference Learning
Exploring SARSA
Section 2: Exploiting the Knowledge
Going Deep with DQN
Going Deeper with DDQN
Policy Gradient Methods
Optimizing for Continuous Control
All about Rainbow DQN
Exploiting ML-Agents
DRL Frameworks
Section 3: Reward Yourself
3D Worlds
From DRL to AGI
Other Books You May Enjoy
Customer Reviews