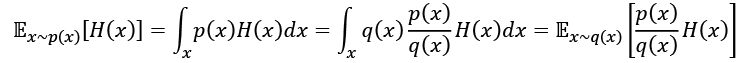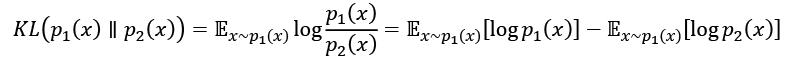-
Book Overview & Buying

-
Table Of Contents

-
Feedback & Rating

Deep Reinforcement Learning Hands-On
By :
Deep Reinforcement Learning Hands-On
By:
Overview of this book
Deep Reinforcement Learning Hands-On, Second Edition is an updated and expanded version of the bestselling guide to the very latest reinforcement learning (RL) tools and techniques. It provides you with an introduction to the fundamentals of RL, along with the hands-on ability to code intelligent learning agents to perform a range of practical tasks.
With six new chapters devoted to a variety of up-to-the-minute developments in RL, including discrete optimization (solving the Rubik's Cube), multi-agent methods, Microsoft's TextWorld environment, advanced exploration techniques, and more, you will come away from this book with a deep understanding of the latest innovations in this emerging field.
In addition, you will gain actionable insights into such topic areas as deep Q-networks, policy gradient methods, continuous control problems, and highly scalable, non-gradient methods. You will also discover how to build a real hardware robot trained with RL for less than $100 and solve the Pong environment in just 30 minutes of training using step-by-step code optimization.
In short, Deep Reinforcement Learning Hands-On, Second Edition, is your companion to navigating the exciting complexities of RL as it helps you attain experience and knowledge through real-world examples.
Table of Contents (28 chapters)
Preface

What Is Reinforcement Learning?
 Free Chapter
Free Chapter
OpenAI Gym
Deep Learning with PyTorch
The Cross-Entropy Method
Tabular Learning and the Bellman Equation
Deep Q-Networks
Higher-Level RL Libraries
DQN Extensions
Ways to Speed up RL
Stocks Trading Using RL
Policy Gradients – an Alternative
The Actor-Critic Method
Asynchronous Advantage Actor-Critic
Training Chatbots with RL
The TextWorld Environment
Web Navigation
Continuous Action Space
RL in Robotics
Trust Regions – PPO, TRPO, ACKTR, and SAC
Black-Box Optimization in RL
Advanced Exploration
Beyond Model-Free – Imagination
AlphaGo Zero
RL in Discrete Optimization
Multi-agent RL
Other Books You May Enjoy
Index
Customer Reviews