





SARSA (whose name is derived from the sequence state-action-reward-state-action) is a natural extension of TD(0) to the estimation of the Q function. Its standard formulation (which is sometimes called one-step SARSA, or SARSA(0), for the same reasons explained in the previous chapter) is based on a single next reward, rt+1, which is obtained by executing the action at in the state st. The temporal difference computation is based on the following update rule:
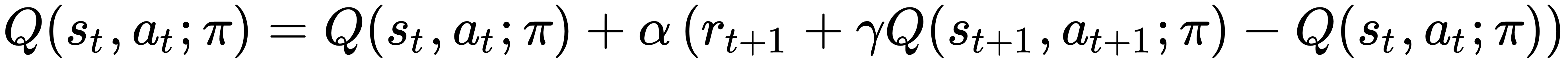
The equation is equivalent to TD(0), and if the policy is chosen to be GLIE, it has been proven (in Convergence Results for Single-Step On-Policy Reinforcement-Learning Algorithms, Singh S., Jaakkola T., Littman M. L., Szepesvári C., Machine Learning, 39/2000) that SARSA converges to an optimal policy, πopt(s), with the probability 1, when all couples (state,...






