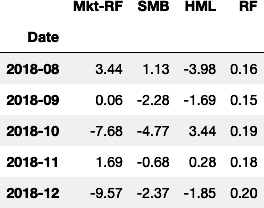
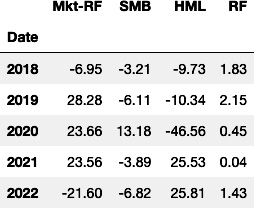
-
Book Overview & Buying

-
Table Of Contents

-
Feedback & Rating

Python for Algorithmic Trading Cookbook
By :
Python for Algorithmic Trading Cookbook
By:
Overview of this book
Discover how Python has made algorithmic trading accessible to non-professionals with unparalleled expertise and practical insights from Jason Strimpel, founder of PyQuant News and a seasoned professional with global experience in trading and risk management. This book guides you through from the basics of quantitative finance and data acquisition to advanced stages of backtesting and live trading.
Detailed recipes will help you leverage the cutting-edge OpenBB SDK to gather freely available data for stocks, options, and futures, and build your own research environment using lightning-fast storage techniques like SQLite, HDF5, and ArcticDB. This book shows you how to use SciPy and statsmodels to identify alpha factors and hedge risk, and construct momentum and mean-reversion factors. You’ll optimize strategy parameters with walk-forward optimization using VectorBT and construct a production-ready backtest using Zipline Reloaded. Implementing all that you’ve learned, you’ll set up and deploy your algorithmic trading strategies in a live trading environment using the Interactive Brokers API, allowing you to stream tick-level data, submit orders, and retrieve portfolio details.
By the end of this algorithmic trading book, you'll not only have grasped the essential concepts but also the practical skills needed to implement and execute sophisticated trading strategies using Python.
Table of Contents (16 chapters)
Preface

 Free Chapter
Free Chapter
Chapter 1: Acquire Free Financial Market Data with Cutting-Edge Python Libraries
Chapter 2: Analyze and Transform Financial Market Data with pandas
Chapter 3: Visualize Financial Market Data with Matplotlib, Seaborn, and Plotly Dash
Chapter 4: Store Financial Market Data on Your Computer
Chapter 5: Build Alpha Factors for Stock Portfolios
Chapter 6: Vector-Based Backtesting with VectorBT
Chapter 7: Event-Based Backtesting Factor Portfolios with Zipline Reloaded
Chapter 8: Evaluate Factor Risk and Performance with Alphalens Reloaded
Chapter 9: Assess Backtest Risk and Performance Metrics with Pyfolio
Chapter 10: Set Up the Interactive Brokers Python API
Chapter 11: Manage Orders, Positions, and Portfolios with the IB API
Chapter 12: Deploy Strategies to a Live Environment
Chapter 13: Advanced Recipes for Market Data and Strategy Management
Index
Customer Reviews