Overview of this book
Generative Adversarial Networks (GANs) have the potential to build next-generation models, as they can mimic any distribution of data. Major research and development work is being undertaken in this field since it is one of the rapidly growing areas of machine learning. This book will test unsupervised techniques for training neural networks as you build seven end-to-end projects in the GAN domain.
Generative Adversarial Network Projects begins by covering the concepts, tools, and libraries that you will use to build efficient projects. You will also use a variety of datasets for the different projects covered in the book. The level of complexity of the operations required increases with every chapter, helping you get to grips with using GANs. You will cover popular approaches such as 3D-GAN, DCGAN, StackGAN, and CycleGAN, and you’ll gain an understanding of the architecture and functioning of generative models through their practical implementation.
By the end of this book, you will be ready to build, train, and optimize your own end-to-end GAN models at work or in your own projects.






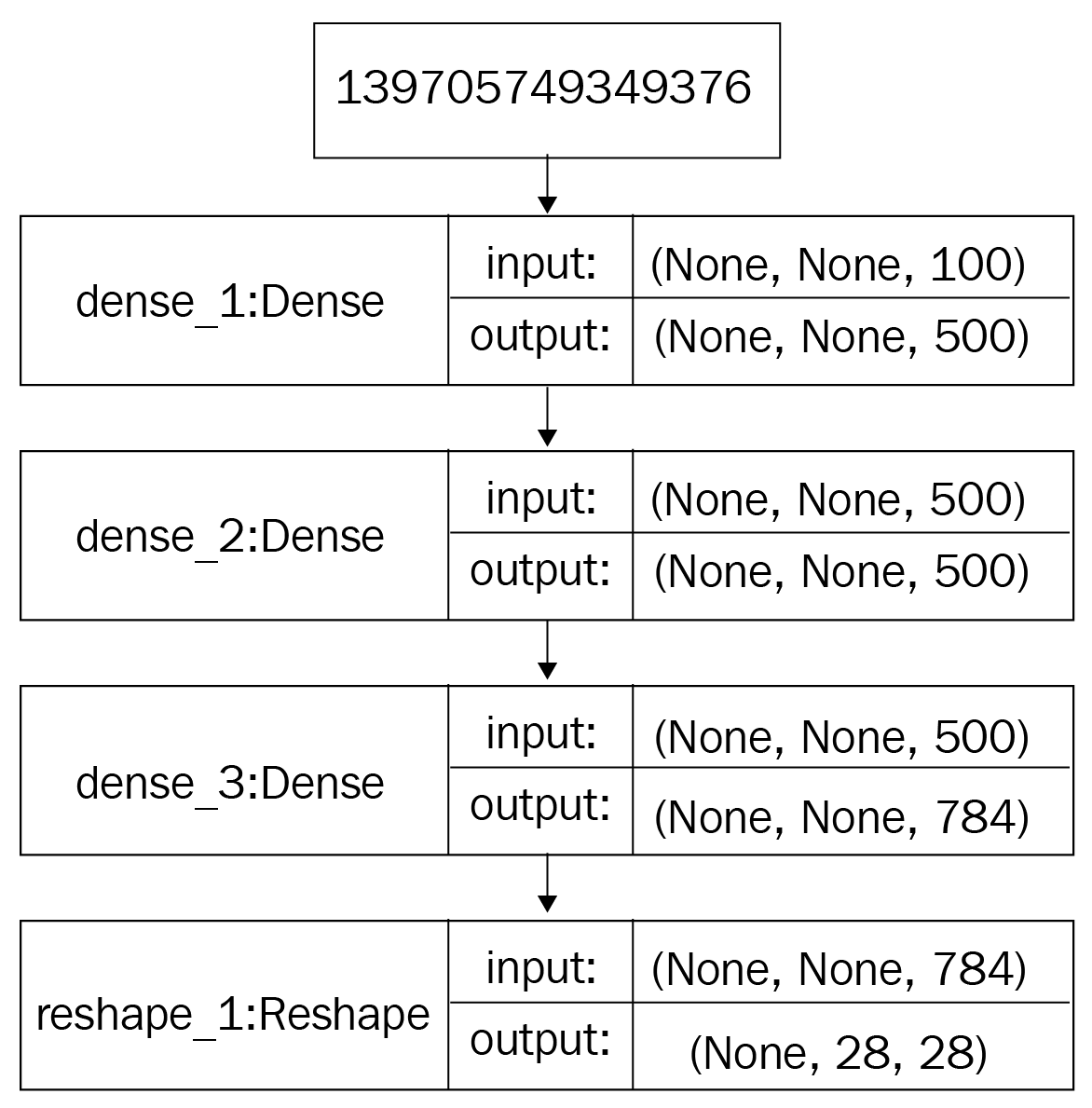
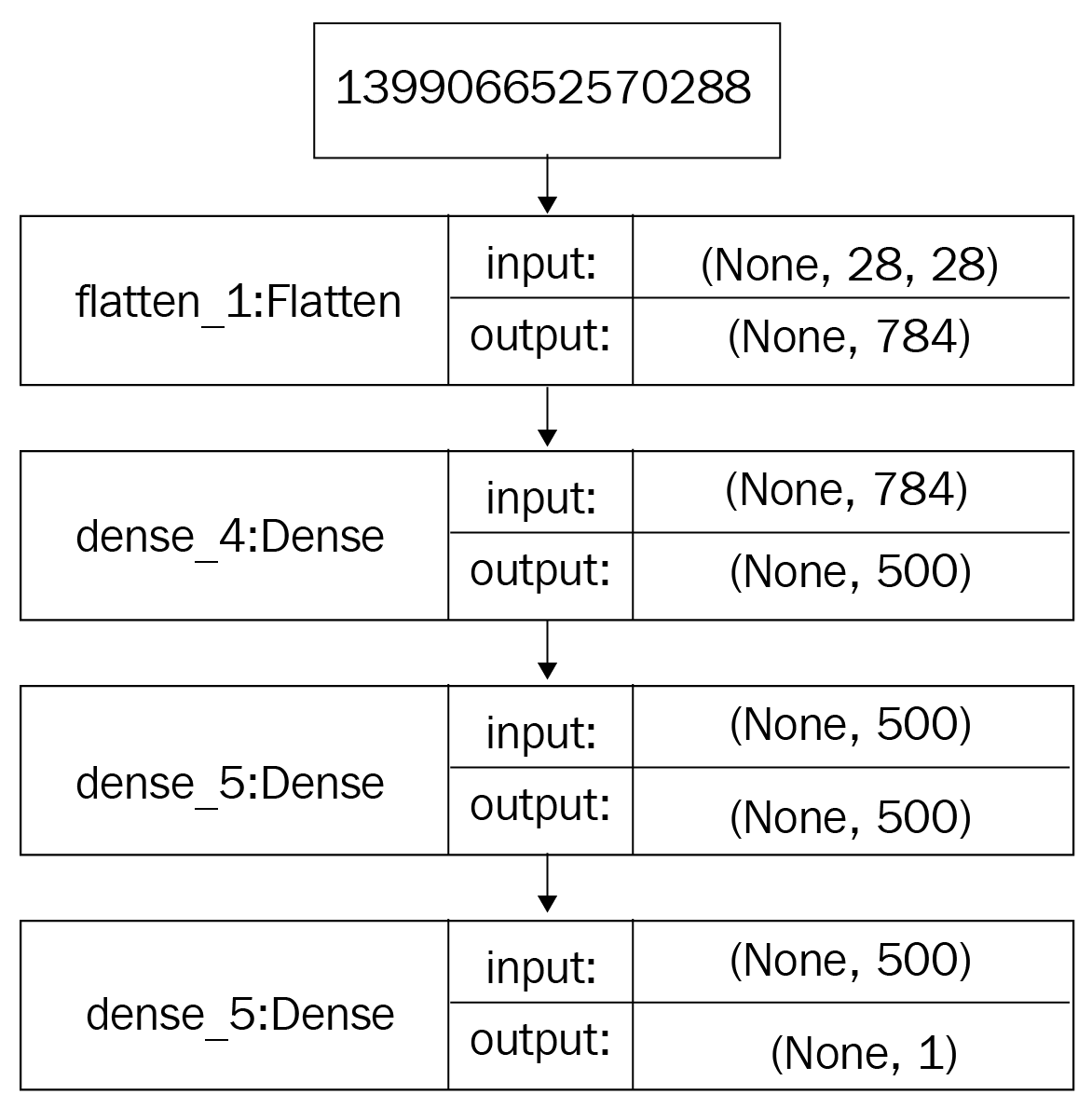

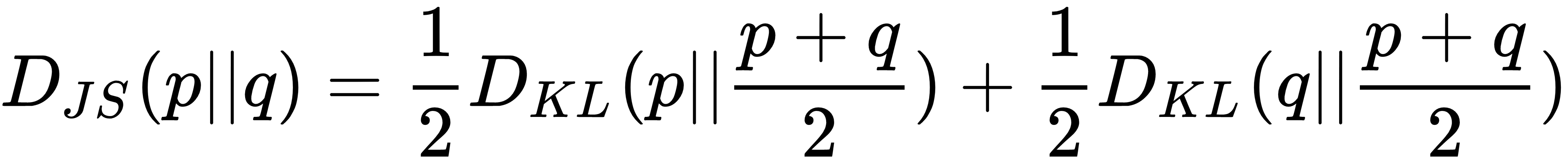
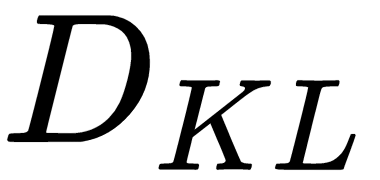 is the Kullback-Leibler divergence.
is the Kullback-Leibler divergence.
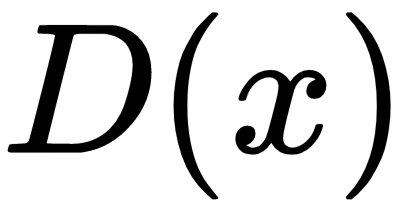 is the discriminator model,
is the discriminator model, 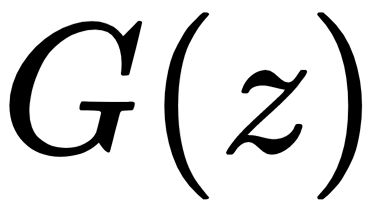 is the generator model,
is the generator model, 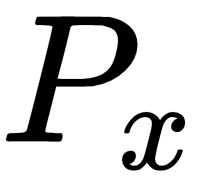 is the real data distribution,
is the real data distribution, 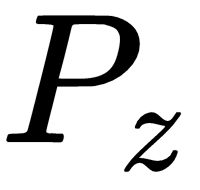 is the distribution of the data generated by the generator, and
is the distribution of the data generated by the generator, and  is the expected output.
is the expected output.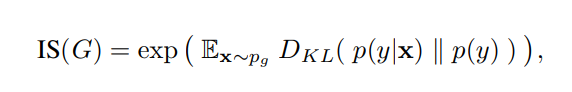
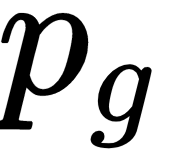 and
and  represent the same concept.
represent the same concept. 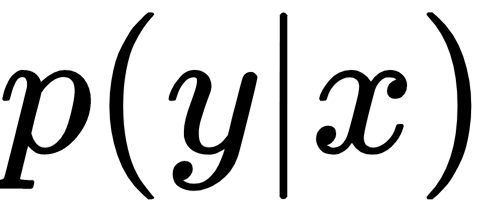 is the conditional class distribution, and
is the conditional class distribution, and 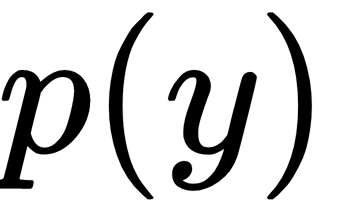 is the marginal class distribution.
is the marginal class distribution.
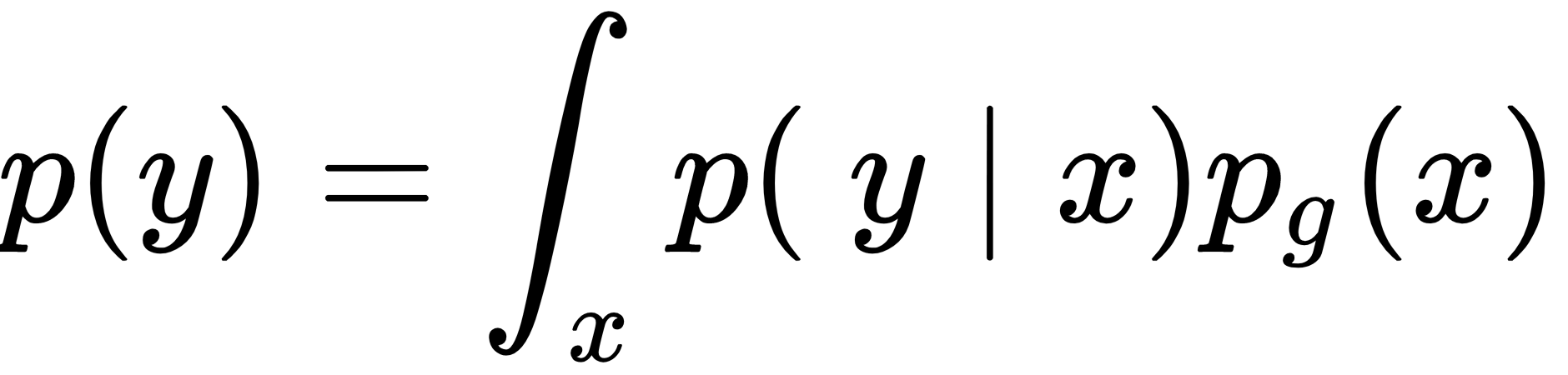
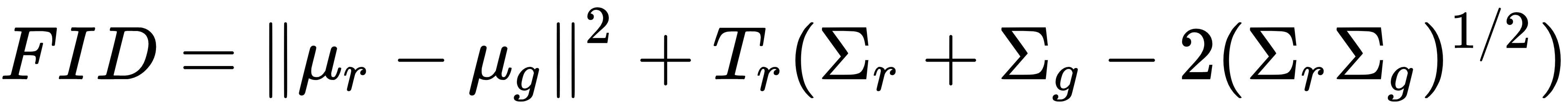
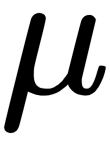 and a covariance of
and a covariance of