-
Book Overview & Buying

-
Table Of Contents

-
Feedback & Rating

Elastic Stack 8.x Cookbook
By :
Elastic Stack 8.x Cookbook
By:
Overview of this book
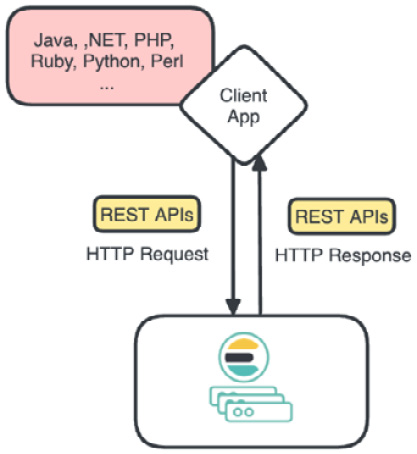
Learn how to make the most of the Elastic Stack (ELK Stack) products—including Elasticsearch, Kibana, Elastic Agent, and Logstash—to take data reliably and securely from any source, in any format, and then search, analyze, and visualize it in real-time. This cookbook takes a practical approach to unlocking the full potential of Elastic Stack through detailed recipes step by step.
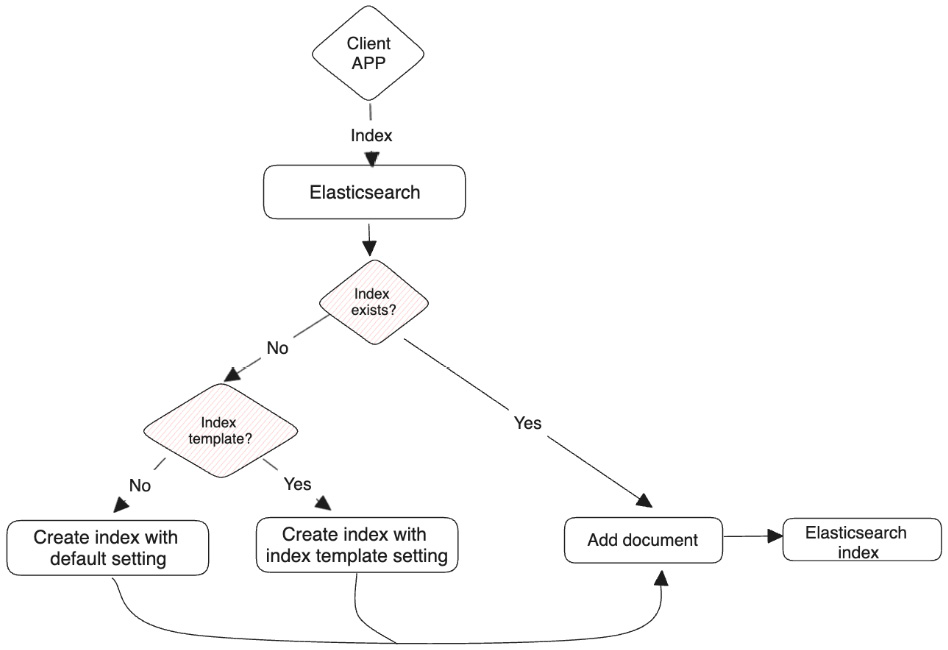
Starting with installing and ingesting data using Elastic Agent and Beats, this book guides you through data transformation and enrichment with various Elastic components and explores the latest advancements in search applications, including semantic search and Generative AI. You'll then visualize and explore your data and create dashboards using Kibana. As you progress, you'll advance your skills with machine learning for data science, get to grips with natural language processing, and discover the power of vector search. The book covers Elastic Observability use cases for log, infrastructure, and synthetics monitoring, along with essential strategies for securing the Elastic Stack. Finally, you'll gain expertise in Elastic Stack operations to effectively monitor and manage your system.
Table of Contents (16 chapters)
Preface

Chapter 1: Getting Started – Installing the Elastic Stack
 Free Chapter
Free Chapter
Chapter 2: Ingesting General Content Data
Chapter 3: Building Search Applications
Chapter 4: Timestamped Data Ingestion
Chapter 5: Transform Data
Chapter 6: Visualize and Explore Data
Chapter 7: Alerting and Anomaly Detection
Chapter 8: Advanced Data Analysis and Processing
Chapter 9: Vector Search and Generative AI Integration
Chapter 10: Elastic Observability Solution
Chapter 11: Managing Access Control
Chapter 12: Elastic Stack Operation
Chapter 13: Elastic Stack Monitoring
Index
Customer Reviews