


-
Book Overview & Buying

-
Table Of Contents

-
Feedback & Rating

A Handbook of Mathematical Models with Python
By :
A Handbook of Mathematical Models with Python
By:
Overview of this book
Mathematical modeling is the art of transforming a business problem into a well-defined mathematical formulation. Its emphasis on interpretability is particularly crucial when deploying a model to support high-stake decisions in sensitive sectors like pharmaceuticals and healthcare.
Through this book, you’ll gain a firm grasp of the foundational mathematics underpinning various machine learning algorithms. Equipped with this knowledge, you can modify algorithms to suit your business problem. Starting with the basic theory and concepts of mathematical modeling, you’ll explore an array of mathematical tools that will empower you to extract insights and understand the data better, which in turn will aid in making optimal, data-driven decisions. The book allows you to explore mathematical optimization and its wide range of applications, and concludes by highlighting the synergetic value derived from blending mathematical models with machine learning.
Ultimately, you’ll be able to apply everything you’ve learned to choose the most fitting methodologies for the business problems you encounter.
Table of Contents (16 chapters)
Preface

Part 1:Mathematical Modeling
 Free Chapter
Free Chapter
Chapter 1: Introduction to Mathematical Modeling
Chapter 2: Machine Learning vis-à-vis Mathematical Modeling
Part 2:Mathematical Tools
Chapter 3: Principal Component Analysis
Chapter 4: Gradient Descent
Chapter 5: Support Vector Machine
Chapter 6: Graph Theory
Chapter 7: Kalman Filter
Chapter 8: Markov Chain
Part 3:Mathematical Optimization
Chapter 9: Exploring Optimization Techniques
Chapter 10: Optimization Techniques for Machine Learning
Index
Customer Reviews
 such that
such that  where i = 1, 2, ...., m
where i = 1, 2, ...., m . These are constrained
. These are constrained 

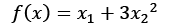
 on a
on a 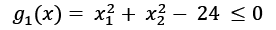
 and
and  are the variables, in general, standing for a matrix or array. The vector
are the variables, in general, standing for a matrix or array. The vector 





