-
Book Overview & Buying

-
Table Of Contents

-
Feedback & Rating

Automated Machine Learning with Microsoft Azure
By :
Automated Machine Learning with Microsoft Azure
By:
Overview of this book
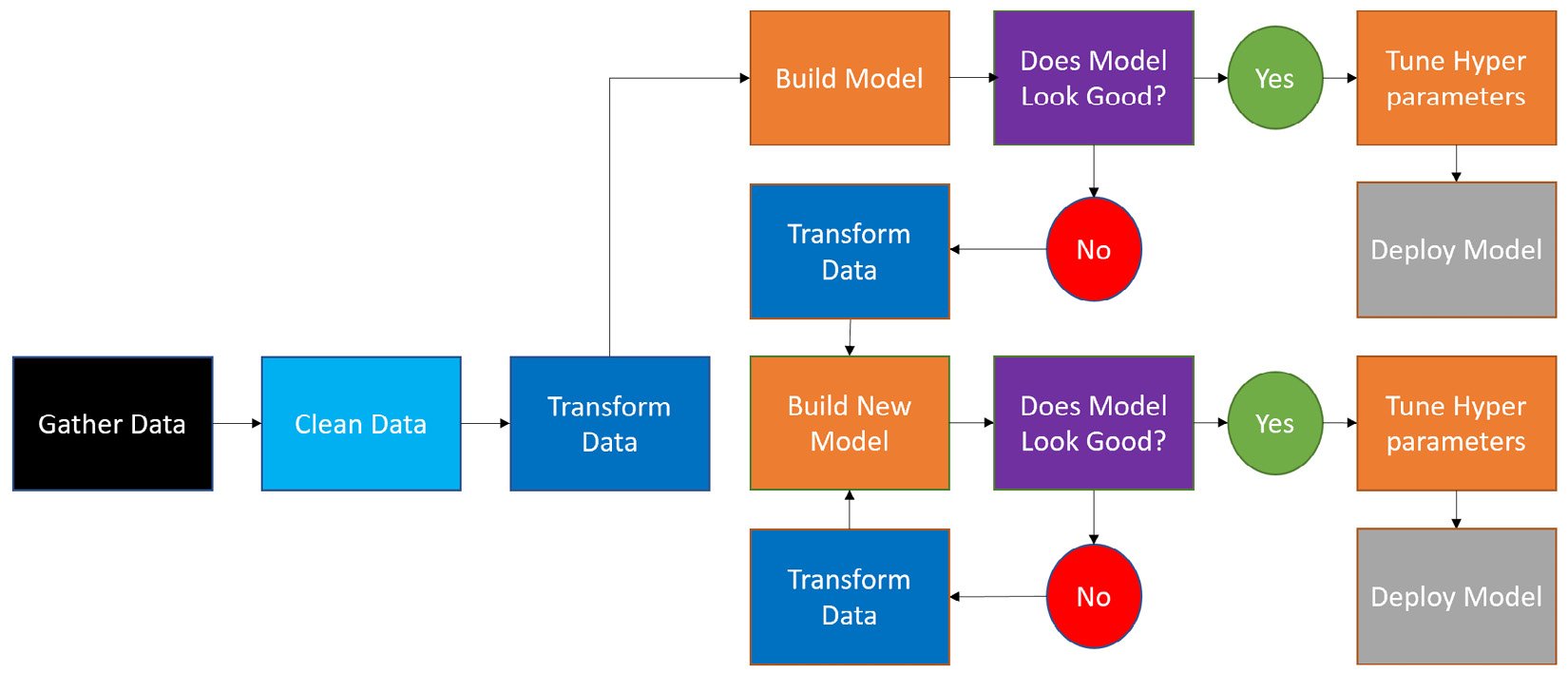
Automated Machine Learning with Microsoft Azure will teach you how to build high-performing, accurate machine learning models in record time. It will equip you with the knowledge and skills to easily harness the power of artificial intelligence and increase the productivity and profitability of your business.
Guided user interfaces (GUIs) enable both novices and seasoned data scientists to easily train and deploy machine learning solutions to production. Using a careful, step-by-step approach, this book will teach you how to use Azure AutoML with a GUI as well as the AzureML Python software development kit (SDK).
First, you'll learn how to prepare data, train models, and register them to your Azure Machine Learning workspace. You'll then discover how to take those models and use them to create both automated batch solutions using machine learning pipelines and real-time scoring solutions using Azure Kubernetes Service (AKS).
Finally, you will be able to use AutoML on your own data to not only train regression, classification, and forecasting models but also use them to solve a wide variety of business problems.
By the end of this Azure book, you'll be able to show your business partners exactly how your ML models are making predictions through automatically generated charts and graphs, earning their trust and respect.
Table of Contents (17 chapters)
Preface

Section 1: AutoML Explained – Why, What, and How
 Free Chapter
Free Chapter
Chapter 1: Introducing AutoML
Chapter 2: Getting Started with Azure Machine Learning Service
Chapter 3: Training Your First AutoML Model
Section 2: AutoML for Regression, Classification, and Forecasting – A Step-by-Step Guide
Chapter 4: Building an AutoML Regression Solution
Chapter 5: Building an AutoML Classification Solution
Chapter 6: Building an AutoML Forecasting Solution
Chapter 7: Using the Many Models Solution Accelerator
Section 3: AutoML in Production – Automating Real-Time and Batch Scoring Solutions
Chapter 8: Choosing Real-Time versus Batch Scoring
Chapter 9: Implementing a Batch Scoring Solution
Chapter 10: Creating End-to-End AutoML Solutions
Chapter 11: Implementing a Real-Time Scoring Solution
Chapter 12: Realizing Business Value with AutoML
Customer Reviews