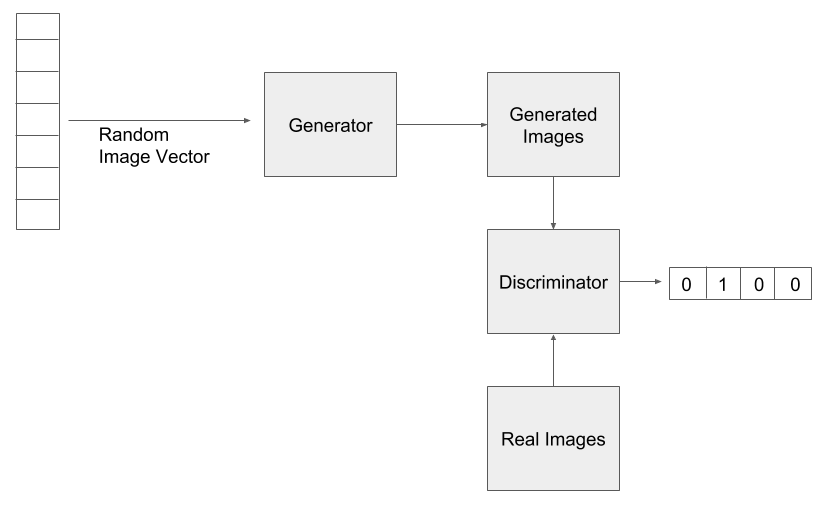
After a brief revision of the key terms, we are now ready to dive deeper into the world of deep learning. In this section, we will be learning about some famous deep learning algorithms and how they work.
-
Book Overview & Buying

-
Table Of Contents

-
Feedback & Rating

Mobile Deep Learning with TensorFlow Lite, ML Kit and Flutter
By :
Mobile Deep Learning with TensorFlow Lite, ML Kit and Flutter
By:
Overview of this book
Deep learning is rapidly becoming the most popular topic in the mobile app industry. This book introduces trending deep learning concepts and their use cases with an industrial and application-focused approach. You will cover a range of projects covering tasks such as mobile vision, facial recognition, smart artificial intelligence assistant, augmented reality, and more.
With the help of eight projects, you will learn how to integrate deep learning processes into mobile platforms, iOS, and Android. This will help you to transform deep learning features into robust mobile apps efficiently. You’ll get hands-on experience of selecting the right deep learning architectures and optimizing mobile deep learning models while following an application oriented-approach to deep learning on native mobile apps. We will later cover various pre-trained and custom-built deep learning model-based APIs such as machine learning (ML) Kit through Firebase. Further on, the book will take you through examples of creating custom deep learning models with TensorFlow Lite. Each project will demonstrate how to integrate deep learning libraries into your mobile apps, right from preparing the model through to deployment.
By the end of this book, you’ll have mastered the skills to build and deploy deep learning mobile applications on both iOS and Android.
Table of Contents (13 chapters)
Preface
Introduction to Deep Learning for Mobile
 Free Chapter
Free Chapter
Mobile Vision - Face Detection Using On-Device Models
Chatbot Using Actions on Google
Recognizing Plant Species
Generating Live Captions from a Camera Feed
Building an Artificial Intelligence Authentication System
Speech/Multimedia Processing - Generating Music Using AI
Reinforced Neural Network-Based Chess Engine
Building an Image Super-Resolution Application
Road Ahead
Other Books You May Enjoy
Customer Reviews