


-
Book Overview & Buying

-
Table Of Contents

-
Feedback & Rating

Functional Python Programming, 3rd edition
By :
Functional Python Programming, 3rd edition
By:
Overview of this book
Not enough developers understand the benefits of functional programming, or even what it is. Author Steven Lott demystifies the approach, teaching you how to improve the way you code in Python and make gains in memory use and performance. If you’re a leetcoder preparing for coding interviews, this book is for you.
Starting from the fundamentals, this book shows you how to apply functional thinking and techniques in a range of scenarios, with Python 3.10+ examples focused on mathematical and statistical algorithms, data cleaning, and exploratory data analysis. You'll learn how to use generator expressions, list comprehensions, and decorators to your advantage. You don't have to abandon object-oriented design completely, though – you'll also see how Python's native object orientation is used in conjunction with functional programming techniques.
By the end of this book, you'll be well-versed in the essential functional programming features of Python and understand why and when functional thinking helps. You'll also have all the tools you need to pursue any additional functional topics that are not part of the Python language.
Table of Contents (18 chapters)
Preface

 Free Chapter
Free Chapter
Chapter 1: Understanding Functional Programming
Chapter 2: Introducing Essential Functional Concepts
Chapter 3: Functions, Iterators, and Generators
Chapter 4: Working with Collections
Chapter 5: Higher-Order Functions
Chapter 6: Recursions and Reductions
Chapter 7: Complex Stateless Objects
Chapter 8: The Itertools Module
Chapter 9: Itertools for Combinatorics – Permutations and Combinations
Chapter 10: The Functools Module
Chapter 11: The Toolz Package
Chapter 12: Decorator Design Techniques
Chapter 13: The PyMonad Library
Chapter 14: The Multiprocessing, Threading, and Concurrent.Futures Modules
Chapter 15: A Functional Approach to Web Services
Other Books You Might Enjoy
Index
Customer Reviews

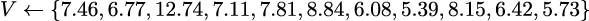
 . See the
. See the 
 .
.
 . Should the code be refactored to match the definition in
. Should the code be refactored to match the definition in 





