-
Book Overview & Buying

-
Table Of Contents

-
Feedback & Rating

The Handbook of NLP with Gensim
By :
The Handbook of NLP with Gensim
By:
Overview of this book
Navigating the terrain of NLP research and applying it practically can be a formidable task made easy with The Handbook of NLP with Gensim. This book demystifies NLP and equips you with hands-on strategies spanning healthcare, e-commerce, finance, and more to enable you to leverage Gensim in real-world scenarios.
You’ll begin by exploring motives and techniques for extracting text information like bag-of-words, TF-IDF, and word embeddings. This book will then guide you on topic modeling using methods such as Latent Semantic Analysis (LSA) for dimensionality reduction and discovering latent semantic relationships in text data, Latent Dirichlet Allocation (LDA) for probabilistic topic modeling, and Ensemble LDA to enhance topic modeling stability and accuracy.
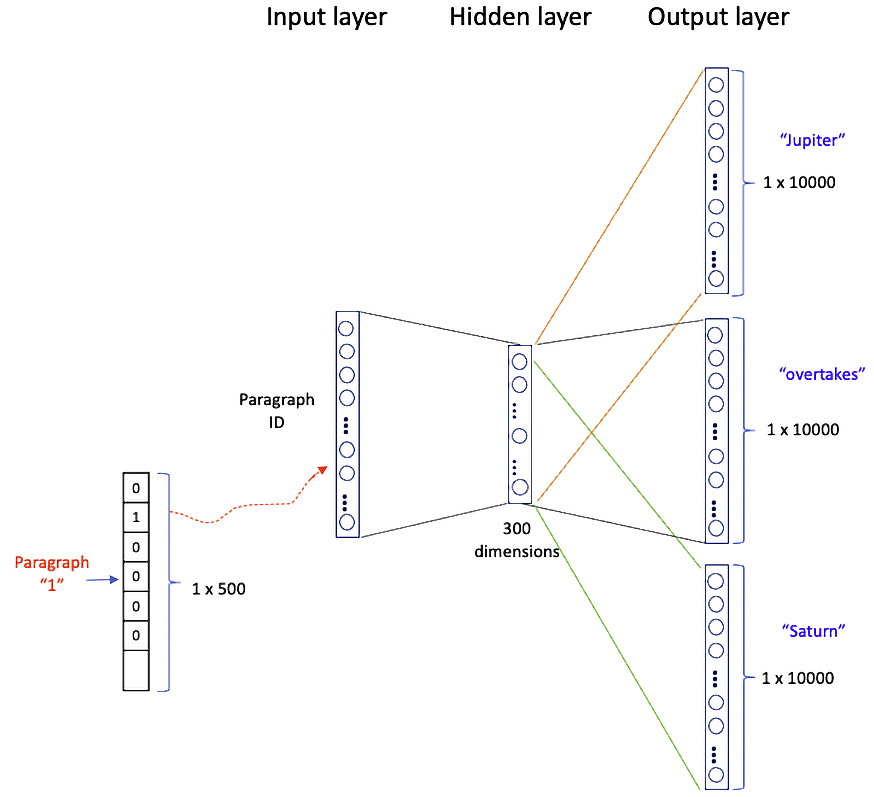
Next, you’ll learn text summarization techniques with Word2Vec and Doc2Vec to build the modeling pipeline and optimize models using hyperparameters. As you get acquainted with practical applications in various industries, this book will inspire you to design innovative projects. Alongside topic modeling, you’ll also explore named entity handling and NER tools, modeling procedures, and tools for effective topic modeling applications.
By the end of this book, you’ll have mastered the techniques essential to create applications with Gensim and integrate NLP into your business processes.
Table of Contents (24 chapters)
Preface

Part 1: NLP Basics
 Free Chapter
Free Chapter
Chapter 1: Introduction to NLP
Chapter 2: Text Representation
Chapter 3: Text Wrangling and Preprocessing
Part 2: Latent Semantic Analysis/Latent Semantic Indexing
Chapter 4: Latent Semantic Analysis with scikit-learn
Chapter 5: Cosine Similarity
Chapter 6: Latent Semantic Indexing with Gensim
Part 3: Word2Vec and Doc2Vec
Chapter 7: Using Word2Vec
Chapter 8: Doc2Vec with Gensim
Part 4: Topic Modeling with Latent Dirichlet Allocation
Chapter 9: Understanding Discrete Distributions
Chapter 10: Latent Dirichlet Allocation
Chapter 11: LDA Modeling
Chapter 12: LDA Visualization
Chapter 13: The Ensemble LDA for Model Stability
Part 5: Comparison and Applications
Chapter 14: LDA and BERTopic
Chapter 15: Real-World Use Cases
Assessments
Index
Customer Reviews