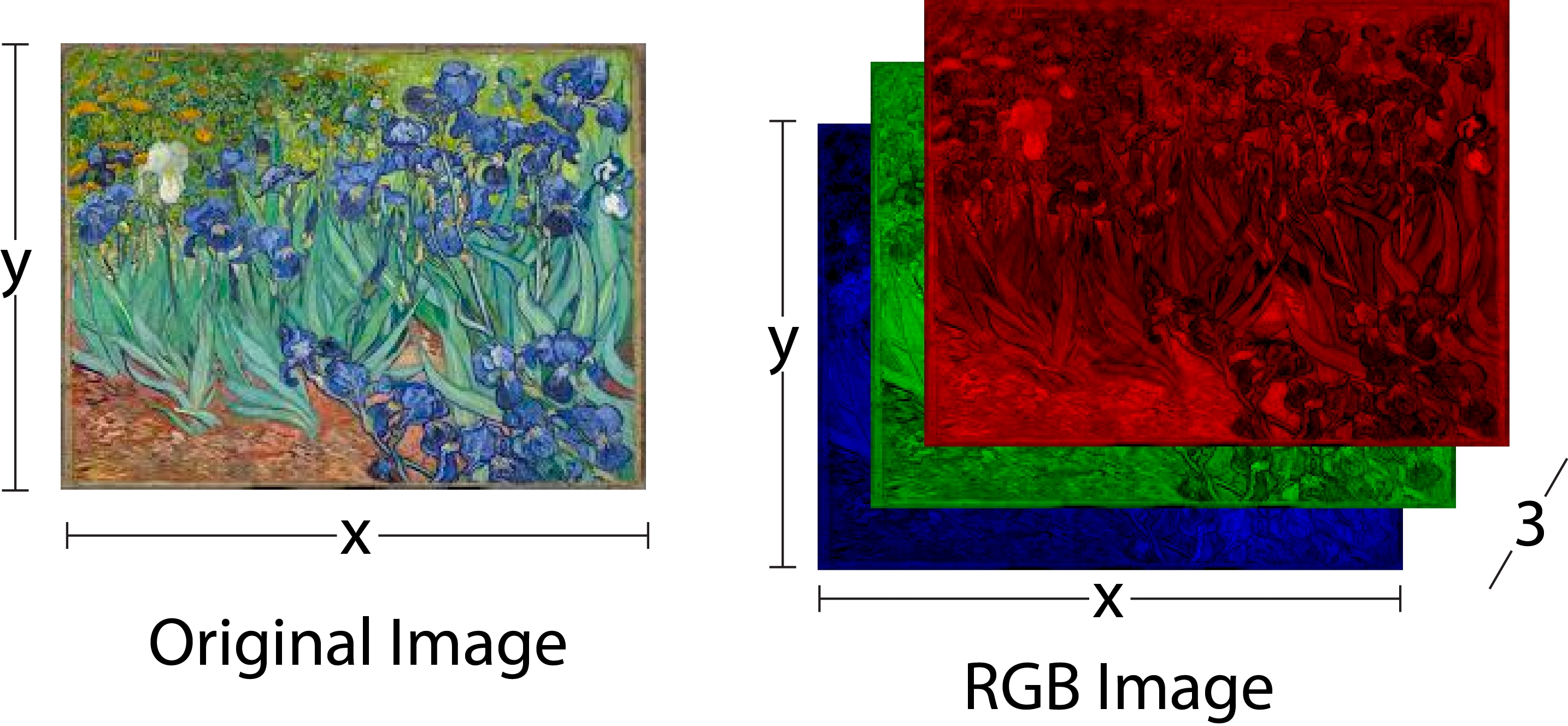
-
Book Overview & Buying

-
Table Of Contents

-
Feedback & Rating

Applied Deep Learning with Keras
By :
Applied Deep Learning with Keras
By:
Overview of this book
Though designing neural networks is a sought-after skill, it is not easy to master. With Keras, you can apply complex machine learning algorithms with minimum code.
Applied Deep Learning with Keras starts by taking you through the basics of machine learning and Python all the way to gaining an in-depth understanding of applying Keras to develop efficient deep learning solutions. To help you grasp the difference between machine and deep learning, the book guides you on how to build a logistic regression model, first with scikit-learn and then with Keras. You will delve into Keras and its many models by creating prediction models for various real-world scenarios, such as disease prediction and customer churning. You’ll gain knowledge on how to evaluate, optimize, and improve your models to achieve maximum information. Next, you’ll learn to evaluate your model by cross-validating it using Keras Wrapper and scikit-learn. Following this, you’ll proceed to understand how to apply L1, L2, and dropout regularization techniques to improve the accuracy of your model. To help maintain accuracy, you’ll get to grips with applying techniques including null accuracy, precision, and AUC-ROC score techniques for fine tuning your model.
By the end of this book, you will have the skills you need to use Keras when building high-level deep neural networks.
Table of Contents (12 chapters)
Applied Deep Learning with Keras

Preface
Preface
 Free Chapter
Free Chapter
Introduction to Machine Learning with Keras
Machine Learning versus Deep Learning
Deep Learning with Keras
Evaluate Your Model with Cross-Validation using Keras Wrappers
Improving Model Accuracy
Model Evaluation
Computer Vision with Convolutional Neural Networks
Transfer Learning and Pre-Trained Models
Sequential Modeling with Recurrent Neural Networks
Customer Reviews