-
Book Overview & Buying

-
Table Of Contents

-
Feedback & Rating

Azure Synapse Analytics Cookbook
By :
Azure Synapse Analytics Cookbook
By:
Overview of this book
As data warehouse management becomes increasingly integral to successful organizations, choosing and running the right solution is more important than ever. Microsoft Azure Synapse is an enterprise-grade, cloud-based data warehousing platform, and this book holds the key to using Synapse to its full potential. If you want the skills and confidence to create a robust enterprise analytical platform, this cookbook is a great place to start.
You'll learn and execute enterprise-level deployments on medium-to-large data platforms. Using the step-by-step recipes and accompanying theory covered in this book, you'll understand how to integrate various services with Synapse to make it a robust solution for all your data needs. Whether you're new to Azure Synapse or just getting started, you'll find the instructions you need to solve any problem you may face, including using Azure services for data visualization as well as for artificial intelligence (AI) and machine learning (ML) solutions.
By the end of this Azure book, you'll have the skills you need to implement an enterprise-grade analytical platform, enabling your organization to explore and manage heterogeneous data workloads and employ various data integration services to solve real-time industry problems.
Table of Contents (11 chapters)
Preface

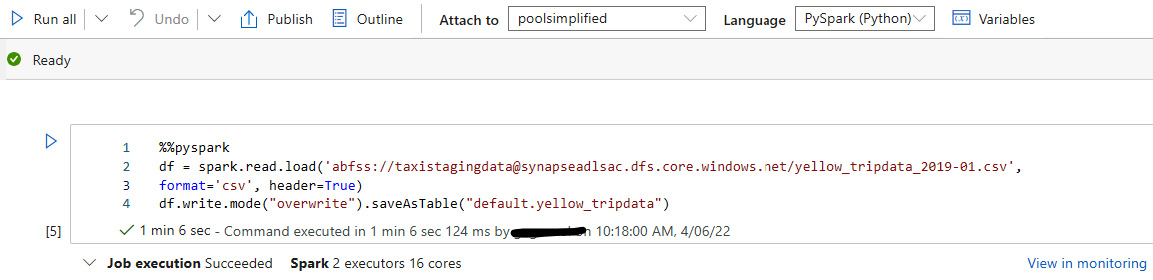
Chapter 1: Choosing the Optimal Method for Loading Data to Synapse
 Free Chapter
Free Chapter
Chapter 2: Creating Robust Data Pipelines and Data Transformation
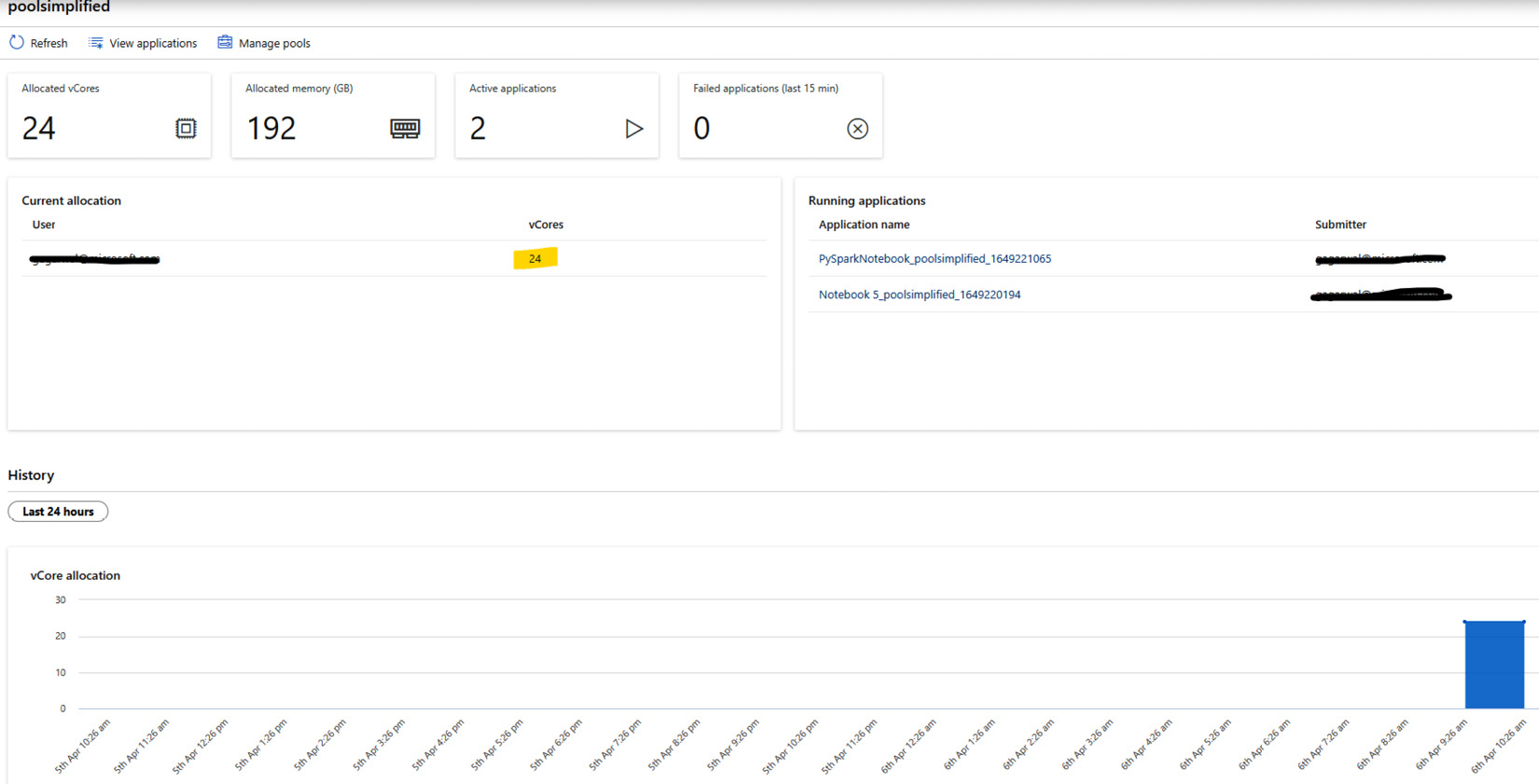
Chapter 3: Processing Data Optimally across Multiple Nodes
Chapter 4: Engineering Real-Time Analytics with Azure Synapse Link Using Cosmos DB
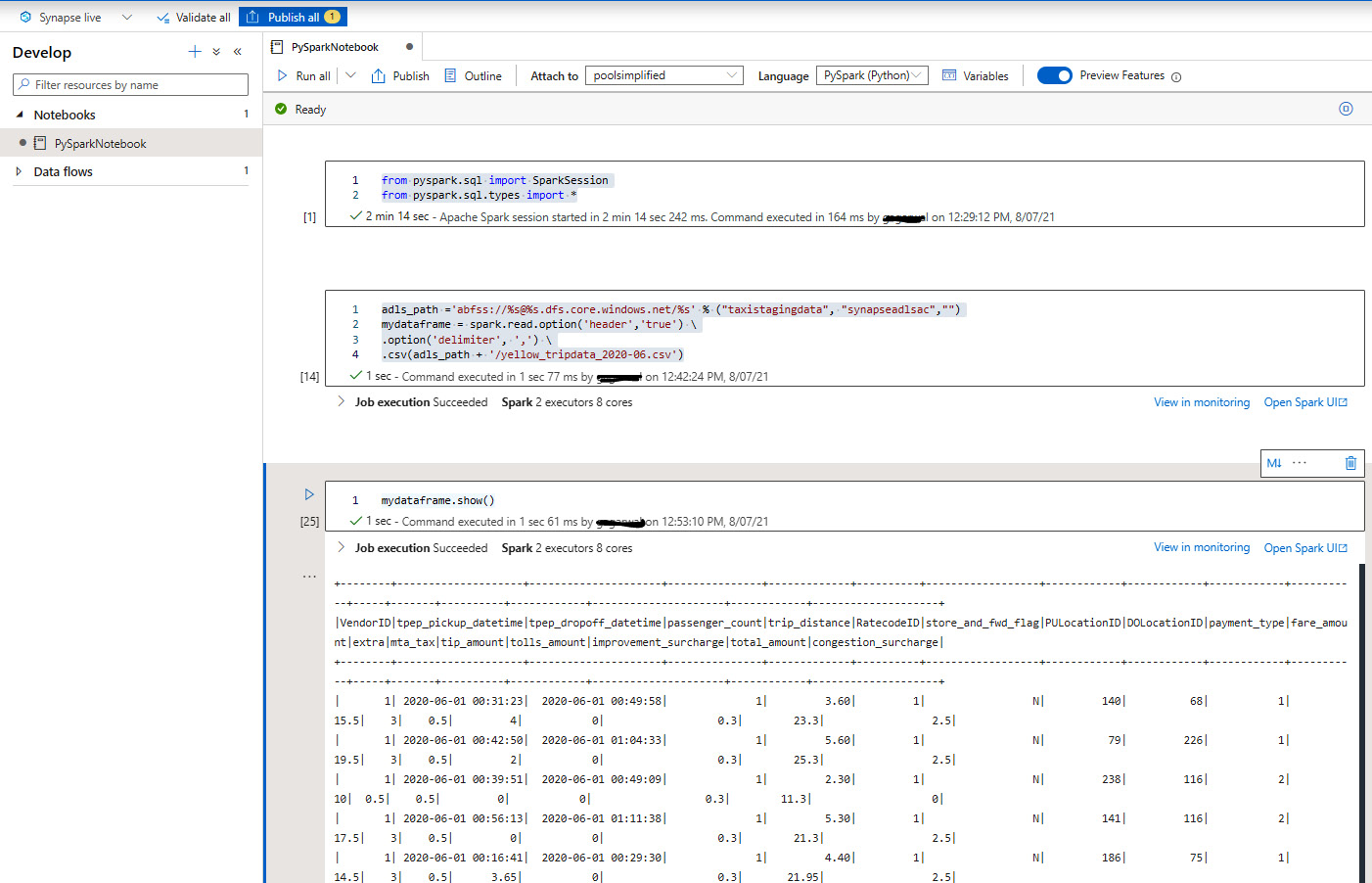
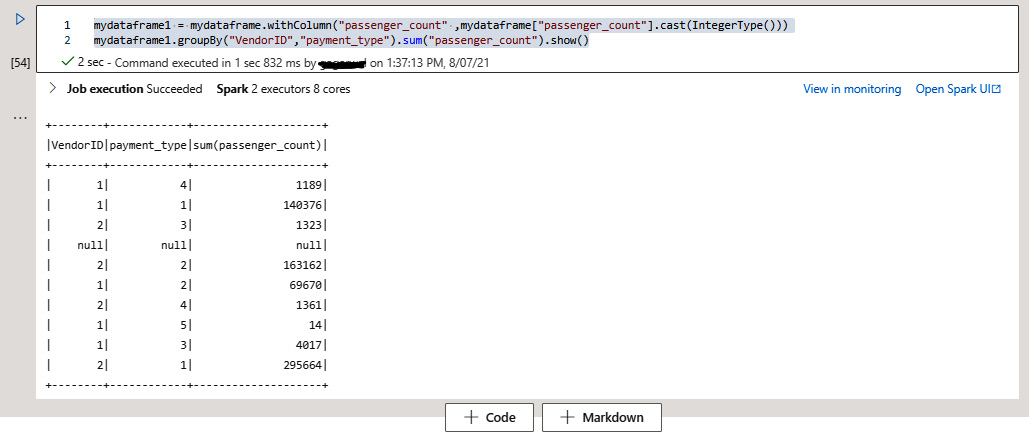
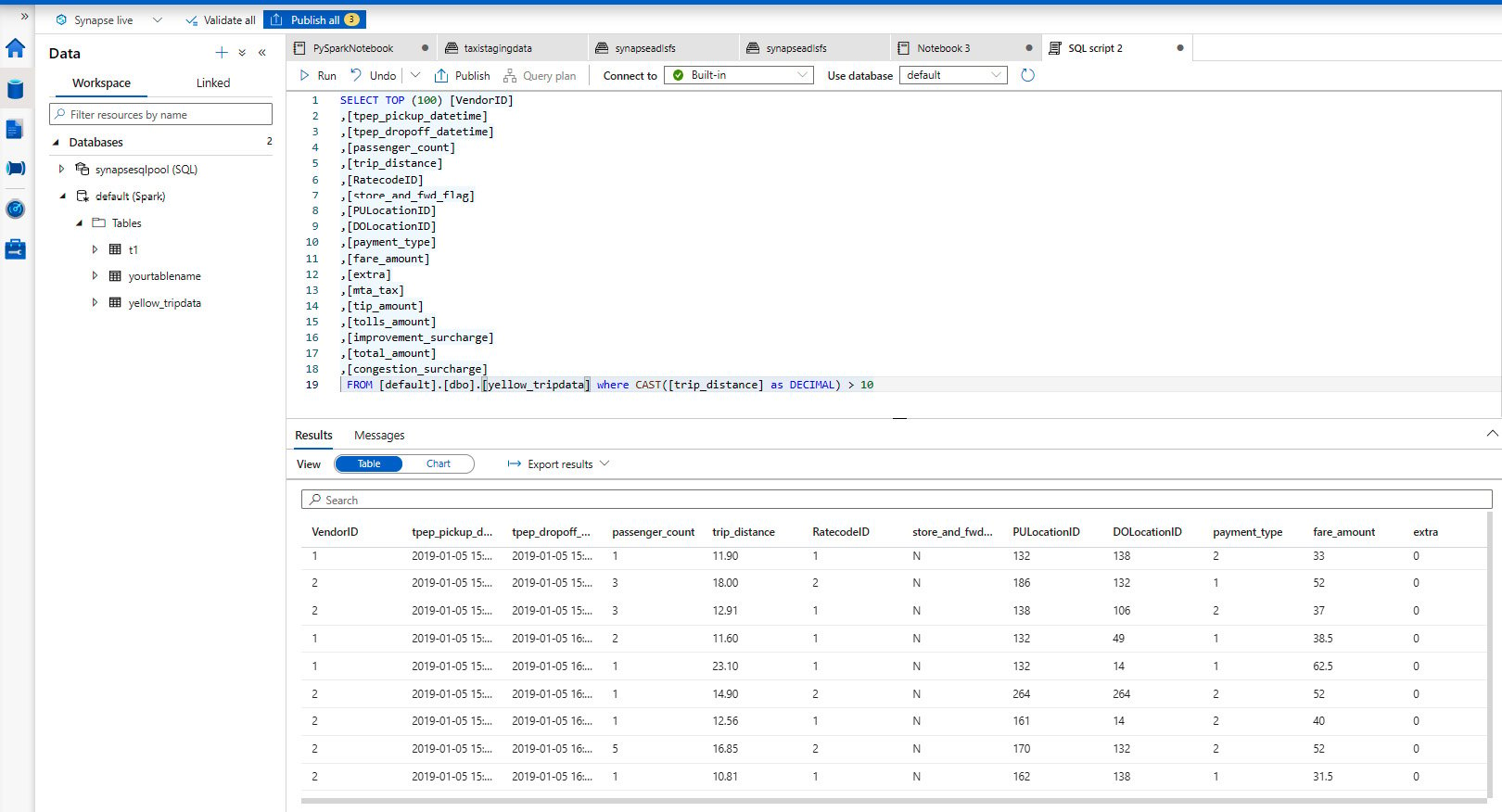
Chapter 5: Data Transformation and Processing with Synapse Notebooks
Chapter 6: Enriching Data Using the Azure ML AutoML Regression Model
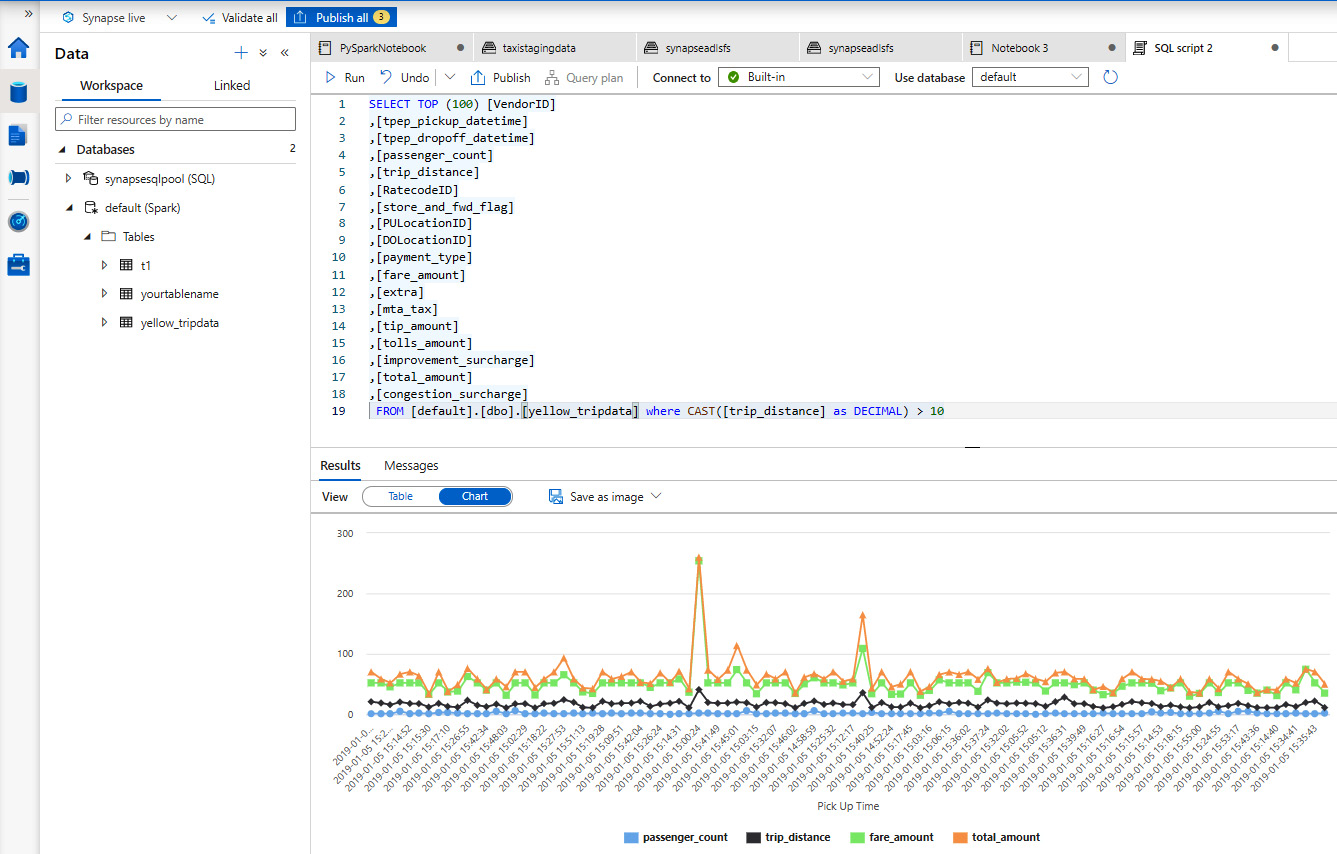
Chapter 7: Visualizing and Reporting Petabytes of Data
Chapter 8: Data Cataloging and Governance
Chapter 9: MPP Platform Migration to Synapse
Other Books You May Enjoy
Customer Reviews