-
Book Overview & Buying

-
Table Of Contents

-
Feedback & Rating

Comet for Data Science
By :
Comet for Data Science
By:
Overview of this book
This book provides concepts and practical use cases which can be used to quickly build, monitor, and optimize data science projects. Using Comet, you will learn how to manage almost every step of the data science process from data collection through to creating, deploying, and monitoring a machine learning model.
The book starts by explaining the features of Comet, along with exploratory data analysis and model evaluation in Comet. You’ll see how Comet gives you the freedom to choose from a selection of programming languages, depending on which is best suited to your needs. Next, you will focus on workspaces, projects, experiments, and models. You will also learn how to build a narrative from your data, using the features provided by Comet. Later, you will review the basic concepts behind DevOps and how to extend the GitLab DevOps platform with Comet, further enhancing your ability to deploy your data science projects. Finally, you will cover various use cases of Comet in machine learning, NLP, deep learning, and time series analysis, gaining hands-on experience with some of the most interesting and valuable data science techniques available.
By the end of this book, you will be able to confidently build data science pipelines according to bespoke specifications and manage them through Comet.
Table of Contents (16 chapters)
Preface

Section 1 – Getting Started with Comet
 Free Chapter
Free Chapter
Chapter 1: An Overview of Comet
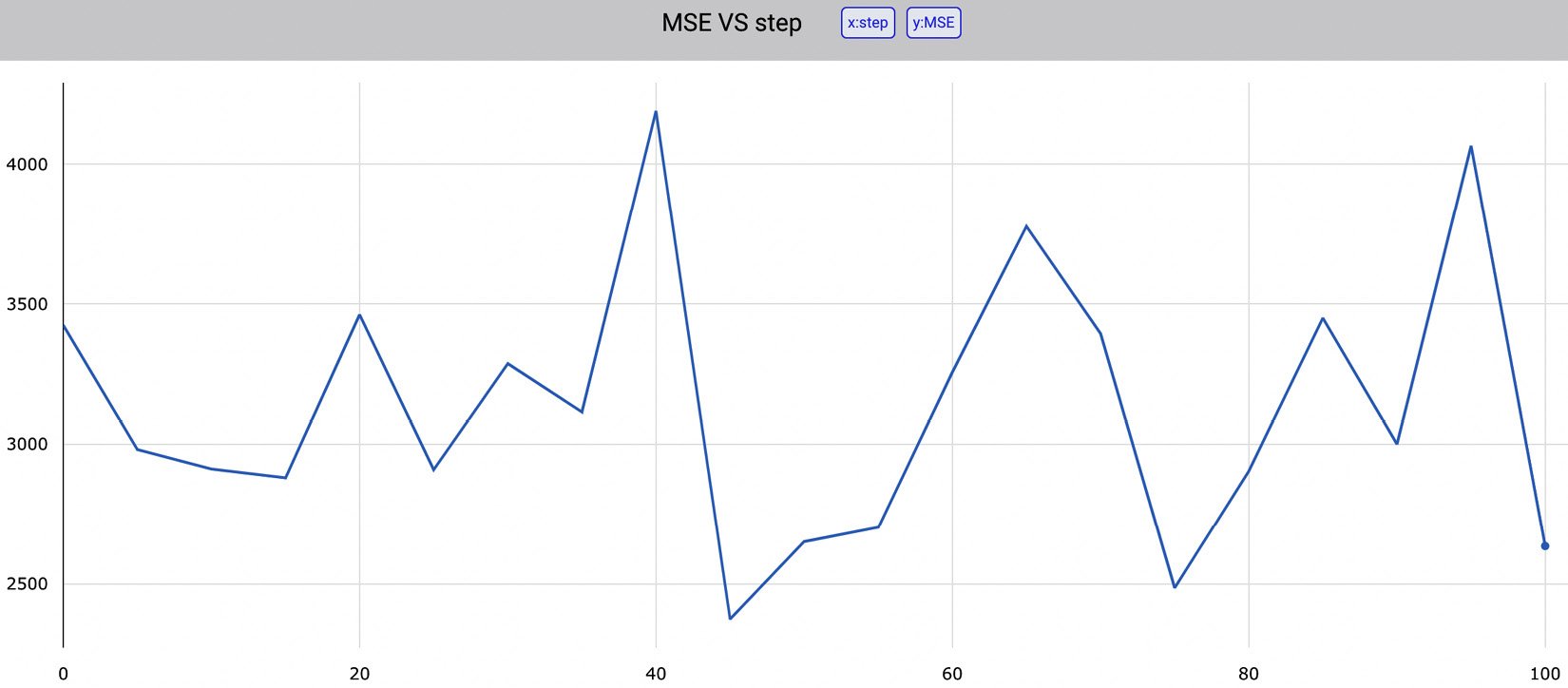
Chapter 2: Exploratory Data Analysis in Comet
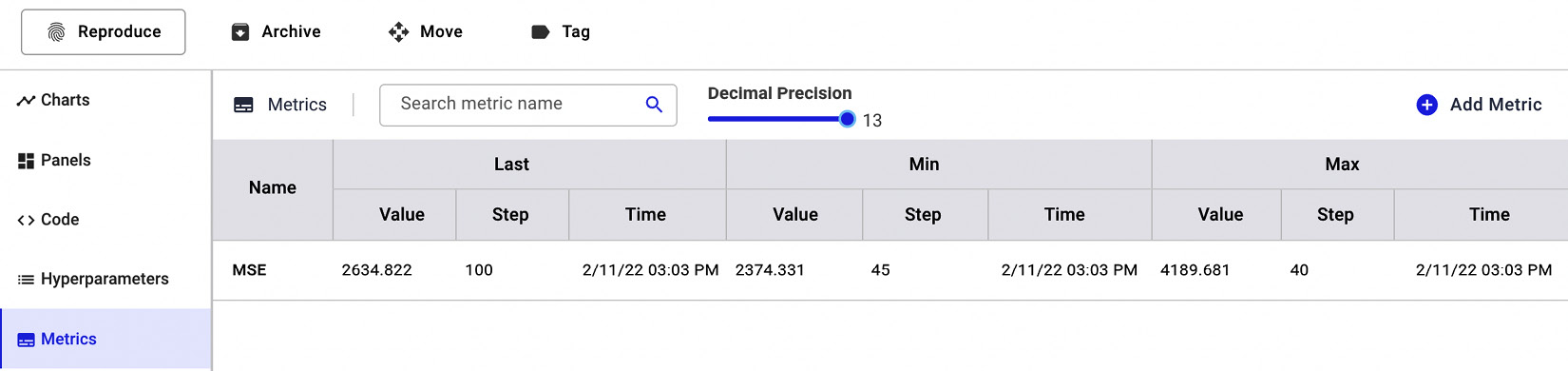
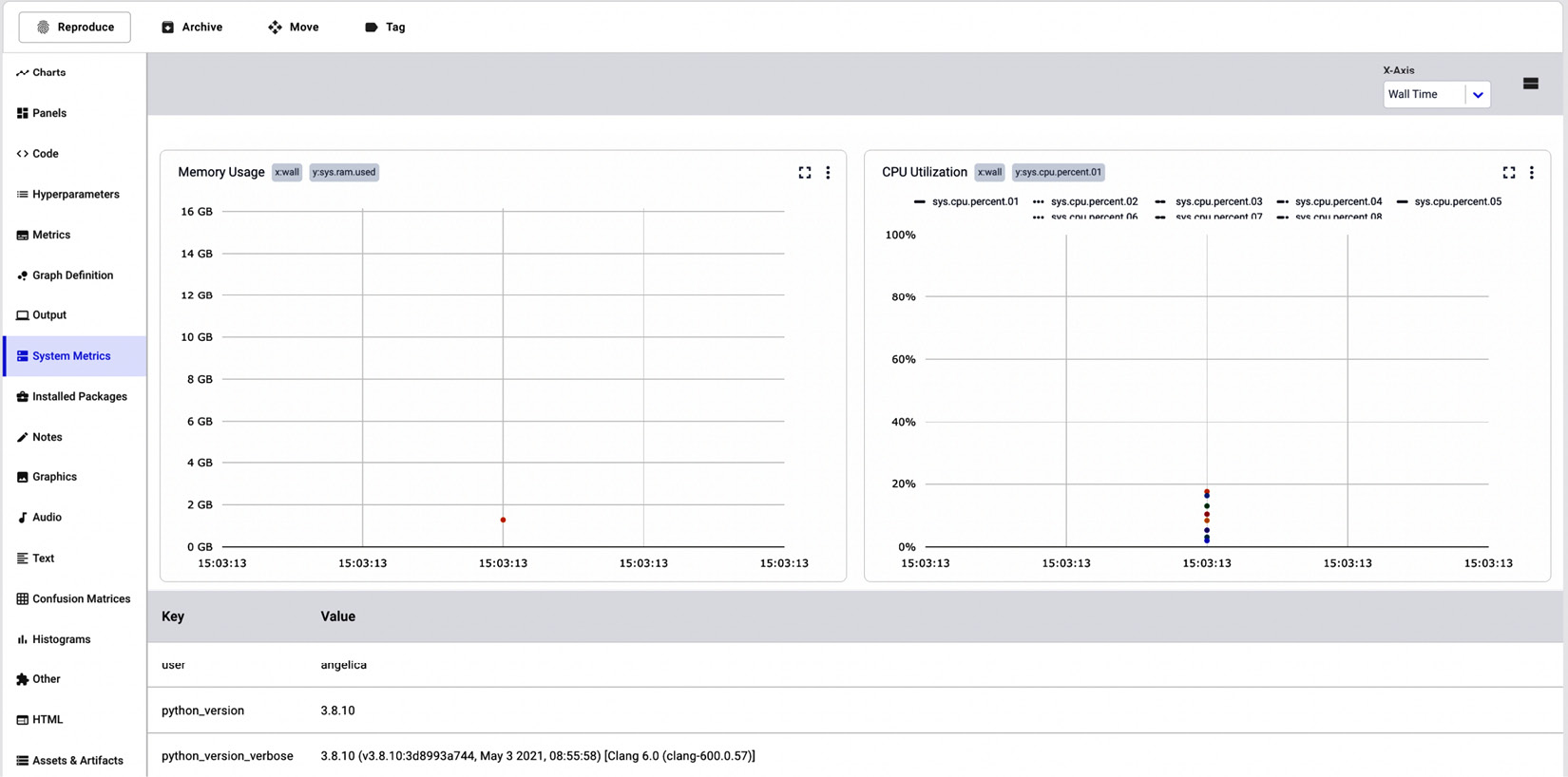
Chapter 3: Model Evaluation in Comet
Section 2 – A Deep Dive into Comet
Chapter 4: Workspaces, Projects, Experiments, and Models
Chapter 5: Building a Narrative in Comet
Chapter 6: Integrating Comet into DevOps
Chapter 7: Extending the GitLab DevOps Platform with Comet
Section 3 – Examples and Use Cases
Chapter 8: Comet for Machine Learning
Chapter 9: Comet for Natural Language Processing
Chapter 10: Comet for Deep Learning
Chapter 11: Comet for Time Series Analysis
Other Books You May Enjoy
Customer Reviews