-
Book Overview & Buying

-
Table Of Contents

-
Feedback & Rating

Data Engineering with Apache Spark, Delta Lake, and Lakehouse
By :
Data Engineering with Apache Spark, Delta Lake, and Lakehouse
By:
Overview of this book
In the world of ever-changing data and schemas, it is important to build data pipelines that can auto-adjust to changes. This book will help you build scalable data platforms that managers, data scientists, and data analysts can rely on.
Starting with an introduction to data engineering, along with its key concepts and architectures, this book will show you how to use Microsoft Azure Cloud services effectively for data engineering. You'll cover data lake design patterns and the different stages through which the data needs to flow in a typical data lake. Once you've explored the main features of Delta Lake to build data lakes with fast performance and governance in mind, you'll advance to implementing the lambda architecture using Delta Lake. Packed with practical examples and code snippets, this book takes you through real-world examples based on production scenarios faced by the author in his 10 years of experience working with big data. Finally, you'll cover data lake deployment strategies that play an important role in provisioning the cloud resources and deploying the data pipelines in a repeatable and continuous way.
By the end of this data engineering book, you'll know how to effectively deal with ever-changing data and create scalable data pipelines to streamline data science, ML, and artificial intelligence (AI) tasks.
Table of Contents (17 chapters)
Preface

Section 1: Modern Data Engineering and Tools
 Free Chapter
Free Chapter
Chapter 1: The Story of Data Engineering and Analytics
Chapter 2: Discovering Storage and Compute Data Lakes
Chapter 3: Data Engineering on Microsoft Azure
Section 2: Data Pipelines and Stages of Data Engineering
Chapter 4: Understanding Data Pipelines
Chapter 5: Data Collection Stage – The Bronze Layer
Chapter 6: Understanding Delta Lake
Chapter 7: Data Curation Stage – The Silver Layer
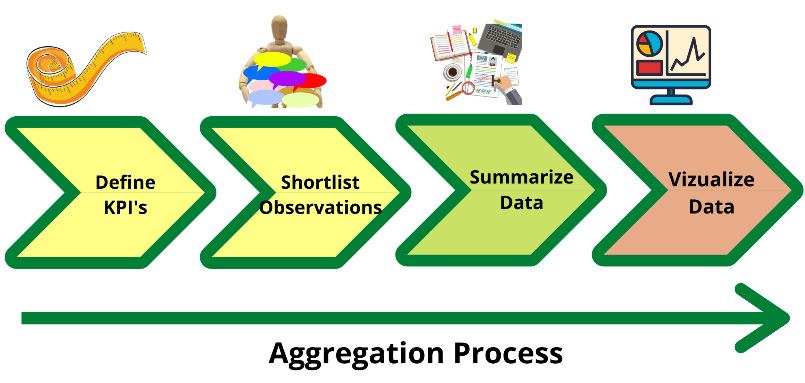
Chapter 8: Data Aggregation Stage – The Gold Layer
Section 3: Data Engineering Challenges and Effective Deployment Strategies
Chapter 9: Deploying and Monitoring Pipelines in Production
Chapter 10: Solving Data Engineering Challenges
Chapter 11: Infrastructure Provisioning
Chapter 12: Continuous Integration and Deployment (CI/CD) of Data Pipelines
Other Books You May Enjoy
Customer Reviews